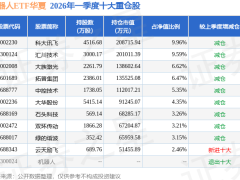
在谷歌2026 I/O開發者大會上,一款名為Gemini Omni的全模態大模型正式亮相,成為全場焦點。這款模型突破了傳統AI在模態處理上的割裂狀態,實現了文本、圖像、音頻、視頻等多種信息形式的深度互通與自由生成。
Gemini Omni的核心能力被概括為“任意輸入、任意輸出”。無論是手繪草圖、文字描述,還是圖片、音頻、視頻素材,用戶都可以自由組合輸入模型。系統能夠自主解析信息邏輯,并模擬真實物理規則,最終生成高精度、符合現實邏輯的多元化內容,包括視頻、圖像和文本等。
支撐這一強大功能的是谷歌的三大核心技術底座:世界模型Genie、圖像模型Nano Banana和視頻生成模型Veo。這三項技術共同構建了Gemini Omni的全模態AI框架,使其能夠處理復雜的多模態任務。
在發布會上,Gemini Omni的對話式實時編輯能力成為最大亮點。與傳統AI生成工具一次性輸出、修改繁瑣不同,這款模型支持用戶在生成過程中通過自然語言對話進行交互式迭代優化。例如,用戶可以精準調整視頻場景、修改物體材質或調整動態特效,而修改過程不會破壞畫面的整體邏輯和物理效果。
現場演示中,工作人員僅用手繪簡易圖形和文字指令,便生成了一段帶有物理碰撞效果的完整特效視頻。這一展示直觀展現了Gemini Omni在內容創作領域的強大潛力,為AI技術的應用開辟了新的可能性。