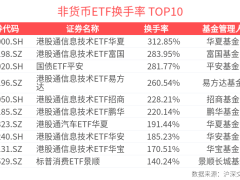
小米近日宣布,其MiMo-V2.5系列API完成永久性價(jià)格調(diào)整,最高降幅達(dá)99%,且不限制輸入長度。這一舉措的背后,是該團(tuán)隊(duì)在推理系統(tǒng)全鏈路優(yōu)化方面取得的重大突破。此次降價(jià)不僅讓用戶直接受益,更標(biāo)志著小米在大模型推理技術(shù)領(lǐng)域?qū)崿F(xiàn)了關(guān)鍵性進(jìn)展。
技術(shù)突破與工程落地之間存在顯著鴻溝。初期主流開源框架對(duì)SWA的支持存在缺陷,實(shí)質(zhì)上是以存儲(chǔ)完整KVCache的代價(jià)兼容SWA模式,導(dǎo)致理論收益難以兌現(xiàn)。小米團(tuán)隊(duì)通過系統(tǒng)性重構(gòu)推理?xiàng)#瑥腒VCache管理、分級(jí)緩存、前綴緩存到調(diào)度策略與Prefill/Decode鏈路進(jìn)行全面優(yōu)化。其中,KVCache雙池分治設(shè)計(jì)將存儲(chǔ)拆分為Full KV Pool與SWA KV Pool,前者按需增長、長期保存,后者采用環(huán)形緩沖區(qū)實(shí)現(xiàn)窗口級(jí)獨(dú)立淘汰,使存儲(chǔ)效率提升約7倍。前綴緩存樹重構(gòu)則通過引入"窗口安全長度"匹配規(guī)則、綁定淘汰路徑與請求生命周期、支持獨(dú)立淘汰策略,將線上前綴緩存命中率提升至平均93%,高頻用戶超過95%。
針對(duì)用戶對(duì)話間隔導(dǎo)致的緩存成本問題,小米自研GCache三級(jí)緩存系統(tǒng)實(shí)現(xiàn)KVCache在GPU顯存、CPU內(nèi)存和NVMe SSD間的自動(dòng)流轉(zhuǎn)。該系統(tǒng)通過RDMA通信實(shí)現(xiàn)170GB/s讀吞吐和280μs延遲,結(jié)合SWA的極小存儲(chǔ)占用,使相同成本下可承載緩存量成倍提升。在調(diào)度優(yōu)化方面,團(tuán)隊(duì)實(shí)現(xiàn)KVCache親和調(diào)度與計(jì)算量感知優(yōu)先調(diào)度,使L2緩存命中率提升25%,TTFT P90降低30%。Prefill鏈路通過縮減Expert Parallelism至原先1/2、采用三級(jí)長度分桶策略,實(shí)現(xiàn)端到端性能提升40%。
Decode階段優(yōu)化聚焦顯存利用率提升。通過支持SWA的KVCache優(yōu)化使有效容量提升近5倍,結(jié)合CUDA Graph顯存調(diào)優(yōu)與PD分離預(yù)分配優(yōu)化,單節(jié)點(diǎn)并發(fā)能力顯著增強(qiáng)。MiMo-V2.5原生支持的3層MTP(Multi-Token Prediction)加速輸出技術(shù),使前128 token加速比達(dá)2.3倍,128-256 token達(dá)1.5倍。在多模態(tài)處理方面,團(tuán)隊(duì)實(shí)現(xiàn)視覺、音頻、視頻跨模態(tài)理解的并行化處理:Encoder支持跨請求組Batch,圖片預(yù)處理遷移至GPU,視頻解碼采用多chunk并行處理,使1小時(shí)視頻端到端延時(shí)從156秒降至23秒,整體Encoder吞吐提升至2倍。
這項(xiàng)覆蓋Hybrid SWA+MoE+多模態(tài)組合架構(gòu)的大規(guī)模工程實(shí)踐,通過系統(tǒng)性優(yōu)化將理論效率優(yōu)勢轉(zhuǎn)化為真實(shí)生產(chǎn)環(huán)境收益。小米已將部分優(yōu)化成果通過PR形式回饋SGLang開源社區(qū),并計(jì)劃持續(xù)推進(jìn)更多開源計(jì)劃,旨在降低工程優(yōu)化門檻,推動(dòng)復(fù)合架構(gòu)的廣泛應(yīng)用。此次API降價(jià)正是技術(shù)突破的直接體現(xiàn),用戶將以更低成本獲得更高性能的模型服務(wù)。