在具身智能技術加速向工廠、家庭和醫療場景滲透的背景下,數據供給不足已成為制約行業規模化落地的核心難題。京東集團近日宣布推出覆蓋全鏈路的數據基礎設施解決方案,通過構建全球最大規模的具身數據采集體系,為行業提供從數據生成到模型優化的閉環支撐。據技術團隊披露,該計劃將發動60萬人參與數據采集,目標在兩年內積累1000萬小時真實場景視頻數據,重點解決機器人訓練數據匱乏的痛點。
京東云自主研發的可穿戴式超高清采集設備JoyEgoCam成為數據采集環節的關鍵突破。這款設備通過優化光學模組與傳輸協議,在物流分揀、手術操作、家庭服務等動態場景中實現4K級視頻的穩定采集。技術負責人介紹,設備內置的AI校準系統可自動修正運動模糊,確保每個動作片段的時空連續性,為后續數據標注提供可靠基礎。
在數據處理層面,京東構建的AI數據湖平臺展現出強大的吞吐能力。該平臺采用分布式計算架構,可每秒處理數萬幀視頻數據,通過自動化的清洗、對齊和預標注流程,將原始數據的利用率提升80%。更值得關注的是JoyBuilder仿真平臺,其通過物理引擎重構真實場景,能將1小時人類操作數據擴展為10小時仿真訓練素材,有效緩解真實數據采集成本高昂的難題。
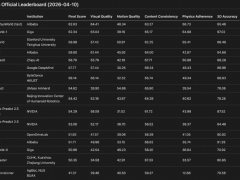
行業調研顯示,當前具身智能模型訓練面臨嚴重的數據鴻溝。京東技術委員會主席曹鵬指出,要訓練出具備跨場景適應能力的通用模型,至少需要千萬小時級的真實交互數據,而現有公開數據集規模不足需求的百分之一。"許多機器人演示時能跳舞翻跟頭,但進入生產線連零件都抓不穩,這就是數據泛化能力缺失的典型表現。"他以工業機械臂為例,說明現有數據集在設備型號、操作流程、環境參數等方面存在嚴重碎片化問題。
京東的數據戰略展現出獨特的生態優勢。依托覆蓋3600個智能倉庫、1.2萬家零售門店和20萬醫藥終端的服務網絡,其數據采集場景天然具備多模態特征。從自動化分揀線的機械臂操作,到藥房抓藥機器人的精準動作,再到家政機器人的復雜環境交互,這些真實業務場景產生的結構化數據,為模型訓練提供了豐富的負樣本和邊緣案例。